1. 架构
mysql的整体架构
innodb引擎原理
- buffer pool
- 三大链表
- ahi
- 双写机制
- 事务的实现
- 事务问题
- acid的解决
- 数据读、写流程
1.1 整体架构
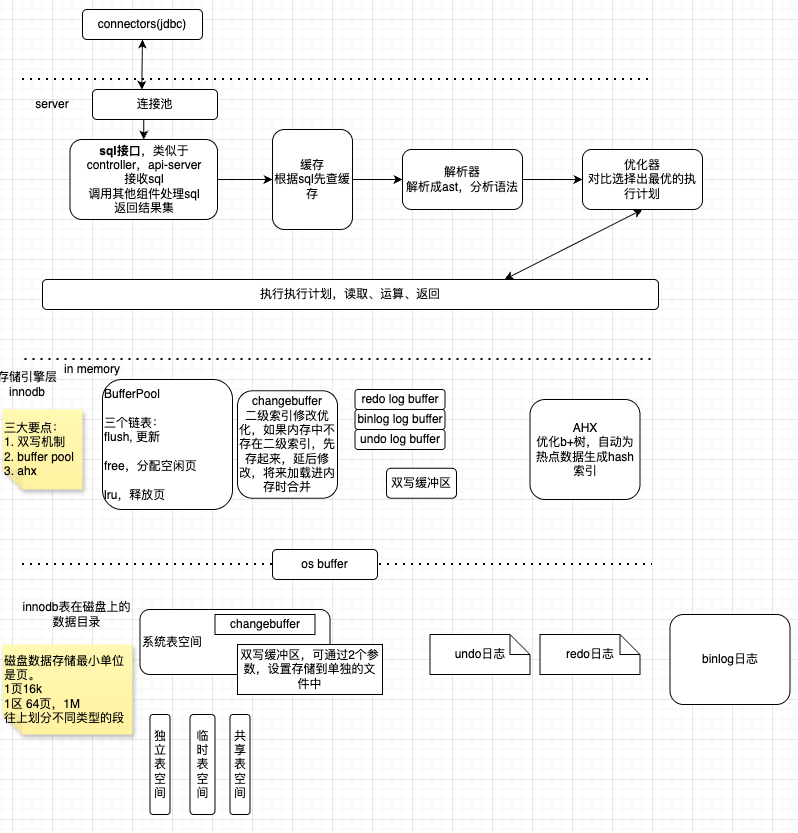
mysql整体可分为三部分,sql server层、存储引擎层、磁盘数据目录层
server层:
- 用户与server层的连接池建立连接,开始使用。
- 调用sql接口,处理sql
- 先对sql进行缓存查询,缓存中没有时才开始sql解析
- 解析器,解析成ast
- 优化器,优化sql,选择出一条成本最低的执行计划
- 然后执行sql
innodb存储引擎层:
- 所有可操作数据页放在buffer pool中,三大链表辅助管理
- ahx,自动为热点数据建立hash索引,提高读写效率
- redo binlog日志 双写缓冲区,防止数据丢失
- undo日志和readview, 实现mvcc,让事务数据只对当前版本可见
磁盘层:
1. 表空间,不同的表空间类型:
1. 系统表空间
1. 双写缓冲区
2. 临时表空间
3. 通用表空间
4. 独立表空间
5. undo 日志
6. redo 日志
7. binlog日志
2. 数据以页存储
1. 1页16K, 64页为1区,1区1M,往上根据不同类型分段
1.2 innodb引擎原理
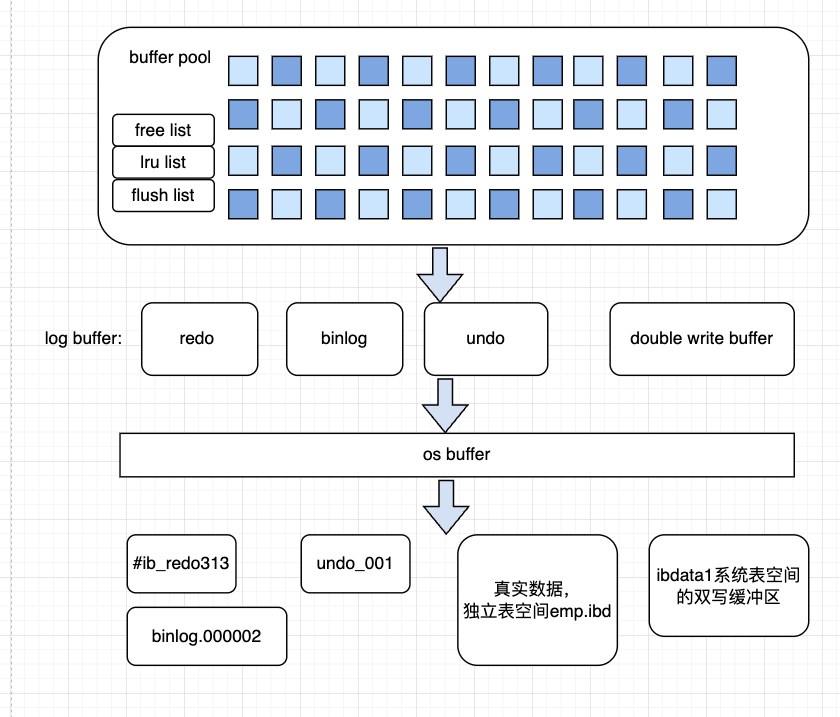
1. buffer pool
磁盘的数据加载到buffer pool上操作。
三大链表辅助:
1. free list: 记录buffer pool上空闲页,插入时分配页
1. lru list: 维护buffer pool的页,是分代模型,young区放热点数据,old区进行新数据进入、旧数据删除、选择新数据进入young区
1. flush list:维护被修改的脏页,双写机制中,第二次写时,刷到磁盘
2. AHI
adaptive hash index
自适应哈希索引
自动为b+索引中的热点数据建立hash索引,是存储在内存中的
3. 双写机制
redo日志,是在数据页级别上的日志。如果页损坏了,就不能恢复。所以需要双写缓冲区。
另外,双写机制是在wal机制运行之后的。
双写:
第一次: 脏页 -> 内存中的双写缓冲区 -> os buffer -> 磁盘的双写缓冲区(可以在系统表空间,也可设置参数指定文件)
第二次: 脏页 -> os buffer -> 磁盘上的真实数据位置
4. 事务实现的原理
- 事务问题:
脏读:读到未提交事务的数据
不可重复读: 两次重复select,会被其他事务的修改影响,查询结果不同
幻读:两次重复查询,第一次没数据,第二次因为新数据的插入,读到了新的数据。
- 事务的隔离级别:
未提交读: 存在脏读
提交读: 存在不可重复读、幻读。此级别的select readview是每次查询都会常见一个,也没有间歇锁
可重复读: 无3种问题。快照读在第一次select时就创建,无论是否有数据都会创建。select... for update 只锁住了当前行,使用间歇锁解决幻读问题。
序列化: 所有事务串行
事务的实现原理
原子性:
同一事务要么全部成功,要么全部失败。
实现思路: 提供回滚机制。
实现: undo日志实现
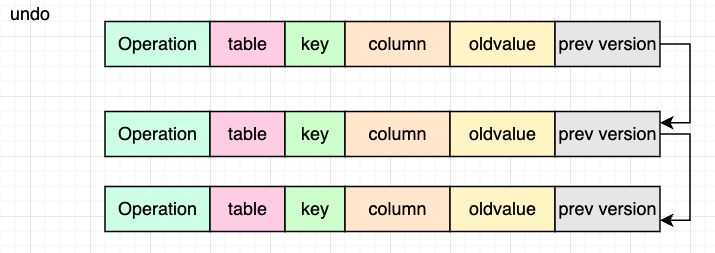
隔离性:
不同事务之间相互隔离
实现思路: mvcc
实现: readview + undo构建对应版本的数据

持久性:
数据持久化
实现: redo日志, binlog日志

一致性:以上因素共同作用的结果
5. 数据读写流程

2. 调优
2.1 索引
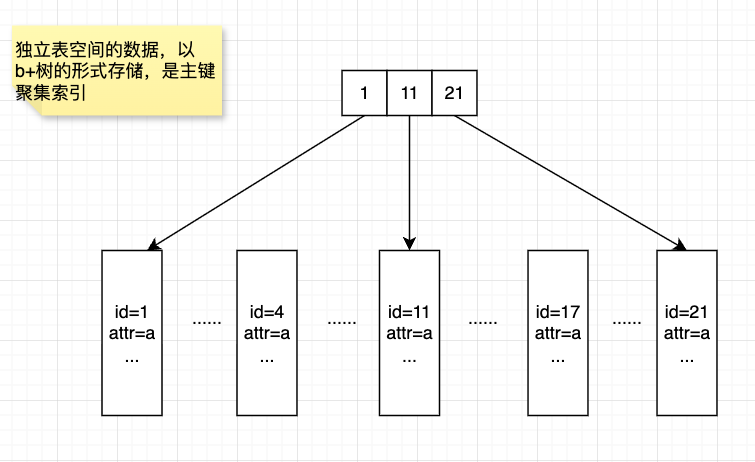
- 分类:
聚集索引
二级索引
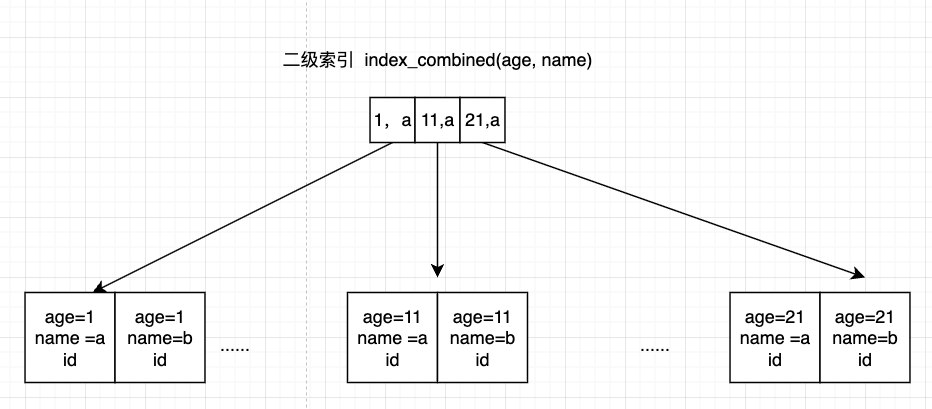
联合索引很重要
最左匹配原则
精确匹配+ 范围匹配, 范围匹配后的索引字段失效
2.2 监控
无监控不调优
查看执行成本
set profiling =1;
show profiles;
performace_shcema数据库
show processlist
explain
show status like 'Handler_read%'; 数据库索引整体使用情况分析
慢查询
- show variables like '%slow_query_log%';
- set global slow_query_log='ON';
- show variables like '%long_query_time%';
- set global long_query_time = 1 ;
- show global variables like ' %long_query_time% ';
- mysqldumpslow -s t -t 5 /var/lib/mysql/demo01-slow.log
- -s sort -t top
2.3 调优
防止索引失效
索引字段使用表达式、类型转换
不符合最左匹配, like, 条件字段的顺序,orderby 的字段顺序
范围匹配之后的索引字段失效
or 不都是索引列
null
优化sql
limit
子查询
join优化
子查询结果集很大用exists 不用in
union 如果不加all,去重的成本有时是很高的